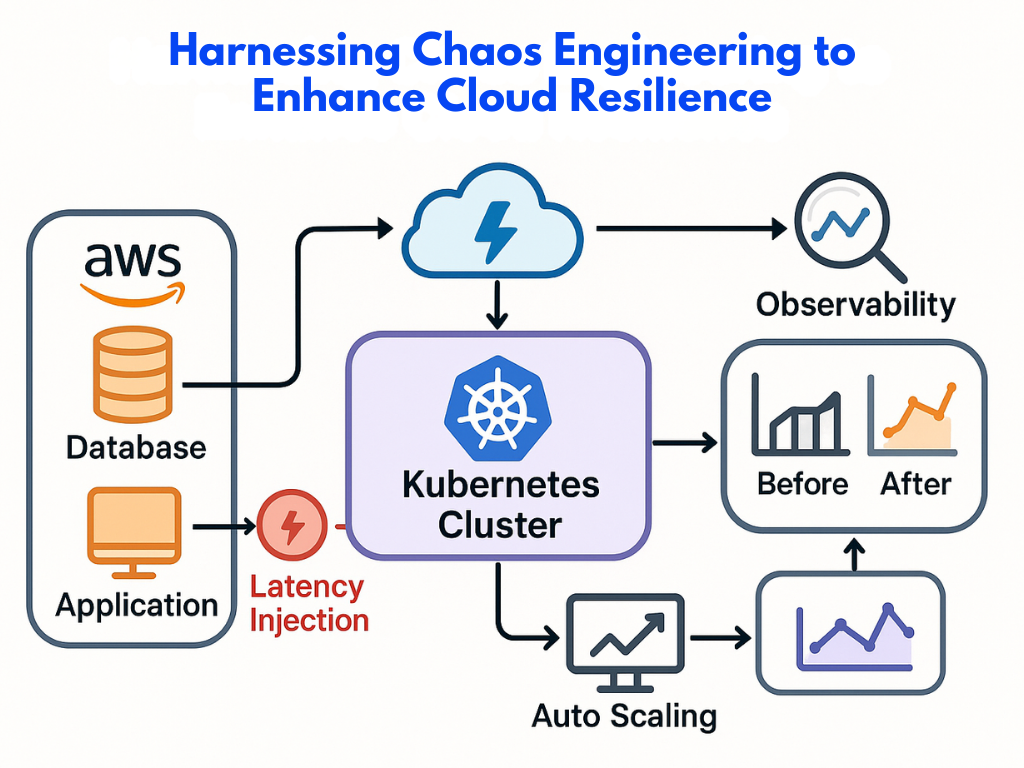
Modern cloud applications are designed for speed, flexibility, and scale—but with that complexity comes fragility. Unexpected outages, cascading failures, or misconfigured systems can bring even the most well-architected services to a halt. The solution? Break your own systems—before they break you.
This is the bold premise behind Chaos Engineering, the discipline of intentionally injecting failures into systems to uncover hidden weaknesses and build true resilience. In this blog, we’ll explore the principles of Chaos Engineering, its value in cloud-native environments, and how to implement it safely and effectively.
What Is Chaos Engineering?
Chaos Engineering is the practice of proactively testing the stability and robustness of systems by simulating real-world failures. The goal isn’t to cause disruption—it’s to ensure that your systems can survive it.
Coined and pioneered by Netflix, Chaos Engineering has evolved into a key strategy for modern DevOps and Site Reliability Engineering (SRE) teams aiming to build highly available and fault-tolerant systems.
Why Chaos Engineering Matters in the Cloud
In the cloud, where systems are distributed, dynamic, and heavily abstracted, the potential points of failure are vast:
- A misbehaving microservice in one region can affect global performance.
- A spike in traffic might expose scaling misconfigurations.
- A misrouted API call could cause a chain of timeouts.
Chaos Engineering gives teams a way to safely discover weaknesses before they manifest in production.
Benefits of Chaos Engineering in Cloud Environments:
- Identify single points of failure in distributed systems.
- Validate auto-scaling and failover configurations.
- Increase confidence in disaster recovery strategies.
- Improve incident response preparedness.
- Build a culture of resilience and learning.
Core Principles of Chaos Engineering
The discipline is guided by a clear methodology. According to the Principles of Chaos Engineering, a successful experiment includes the following steps:
1. Define the “Steady State”
Understand what normal behavior looks like—key metrics such as response time, error rates, or throughput.
2. Form a Hypothesis
Predict how the system should behave when subjected to a specific failure scenario.
3. Introduce Realistic Faults
Simulate events like server crashes, latency injections, dependency failures, or region outages.
4. Observe and Measure
Compare system behavior against the steady state. Did it degrade gracefully? Were alerts triggered? Did users notice?
5. Minimize Blast Radius
Always start small. Limit experiments to a subset of traffic, infrastructure, or environments to reduce risk.
Common Chaos Engineering Scenarios in the Cloud
Here are examples of faults commonly tested in real-world cloud environments:
| Scenario | Purpose |
| Instance termination | Verify service redundancy and failover |
| Network latency injection | Test timeout handling and user experience under stress |
| Dependency outage | Validate circuit breakers and fallback mechanisms |
| Autoscaling failures | Ensure scaling policies respond correctly under pressure |
| Region failover simulation | Check resilience across availability zones or cloud regions |
| DNS misrouting | Test the system’s ability to recover from configuration errors |
Tools for Running Chaos Experiments
Several tools make it easier to conduct controlled chaos experiments in cloud-native environments:
1. AWS Fault Injection Service (FIS)
A managed service that enables you to run fault injection experiments directly on AWS infrastructure with built-in safety controls.
2. Chaos Mesh (for Kubernetes)
An open-source chaos orchestrator designed for Kubernetes. Ideal for cloud-native applications using containers and microservices.
3. Gremlin
A commercial chaos engineering platform that supports safe, scalable experiments with detailed audit and blast radius control.
4. LitmusChaos
Open-source framework for Kubernetes-native chaos experiments. Integrates well with CI/CD pipelines and observability tools.
Best Practices for Implementing Chaos Engineering in the Cloud
1. Start in Lower Environments
Don’t begin with production. Start in staging or dev, and graduate to production with limited scope experiments only when confidence is high.
2. Build Cross-Functional Buy-In
Involve developers, SREs, QA, and leadership. Chaos Engineering is a team sport.
3. Use Observability Tools
Monitor everything. Pair chaos experiments with tools like CloudWatch, Datadog, Prometheus, or Grafana to analyze impact and outcomes.
4. Automate, but Thoughtfully
Integrate chaos into CI/CD pipelines for continuous validation, but ensure you have gates to avoid automated disasters.
5. Learn from Every Experiment
Treat every test as a learning opportunity. Document findings, improve runbooks, and strengthen your incident response strategy.
Real-World Example: Chaos Engineering in a FinTech Platform
A financial services platform running on AWS wanted to ensure resilience during high-traffic trading hours. Using AWS Fault Injection Service, the team:
- Simulated EC2 instance failures across multiple AZs.
- Injected latency into third-party API calls for market data.
- Validated autoscaling policies and service timeouts.
The result? They uncovered a hidden dependency on a non-redundant logging system, fixed it, and documented a more robust recovery workflow—before any customer impact occurred in production.
Chaos Engineering and the DevOps Pipeline
Chaos Engineering isn’t a standalone initiative—it’s an extension of your DevOps and SRE culture. When integrated with tools like Infrastructure as Code, CI/CD, and observability stacks, chaos experiments can become a natural part of your software delivery lifecycle.
- Before release: Validate system behavior under simulated failures.
- During release: Run fault tests on canary deployments.
- After release: Measure how changes affect fault tolerance.
Conclusion
In cloud-native systems, failures are inevitable—but downtime doesn’t have to be. Chaos Engineering enables teams to build confidence through controlled failure, uncovering fragility and reinforcing systems before users ever feel the impact.
When applied thoughtfully, Chaos Engineering transforms your cloud environment from a ticking time bomb into a self-healing, high-availability ecosystem. It’s not just about surviving chaos—it’s about embracing it as a tool for growth.